画像キャプチャサービス「Gyazo」と関連画像検索システム
画像キャプチャサービス「Gyazo」と関連画像検索システム
増井俊之
慶應義塾大学
2017/3/13

自己紹介
シャープ、ソニー、産総研などに勤務
ケータイの予測変換(POBox)などを開発
2008秋まで米国Appleに勤務
フリック入力システムなどを開発
2009より慶應義塾大学
ユーザインタフェースの研究開発
IoT, 検索システム, 情報視覚化
各種Webサービス運用中
Gyazo, Scrapbox, 本棚.org, ...
POBox

POBox on Palm

「フリック」入力
光文社新書

煽り

増井の研究開発方針
自分の欲しいものを作る
自分で使う
コロンブスの卵が好き
今すぐ使えて売れるものを作る
コロンブス日和

GyaTV (2015/11)
Gyump (2015/12)
Gyamm (2016/1)
Gyazo (2016/2)
Gyaki (2016/3)
Dynamic Macro (2016/4)
Gyaim (2016/5)
EpisoPass (2016/6)
ExpandHelp (2016/7)
DragZoom (2016/8)
Gear (2016/9)
SmoothSnap (2016/10)
廃れるページ (2016/11)
HashInfo (2016/12)
フラット整理術 (2017/1)
Scrapbox(1) (2017/2)
Scrapbox(2) (2017/3)
発見プログラミング (2017/4) = 最終回
ドッグフーディング
Eat your own dogfood
自分で作ったものを使い倒して改善する
Gyazoとは
超簡単な画像アップロードサービス
Gyazoキー

デモ: Gyazo
Gyazo (2010/7)
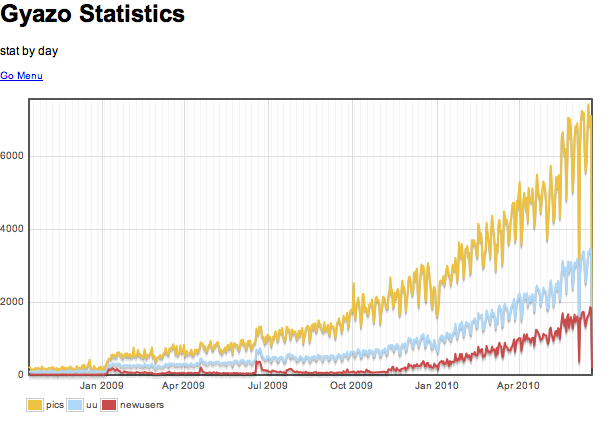
Gyazo (2012/1)
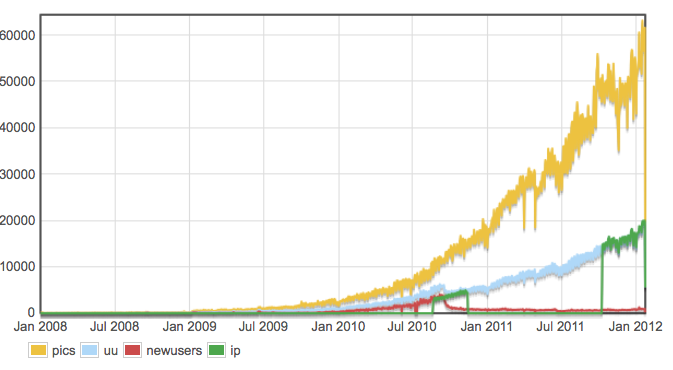
Gyazo (2014/1)
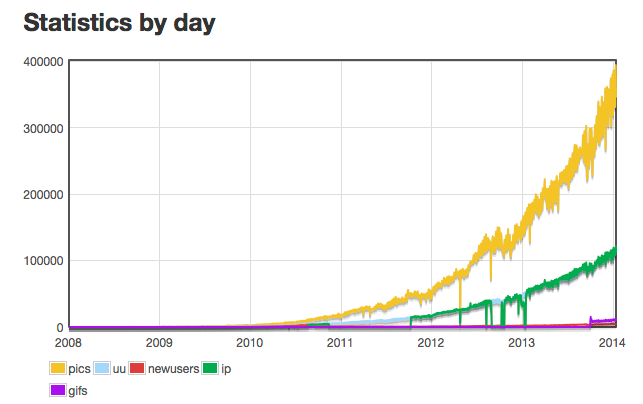
Gyazo (2015/1)
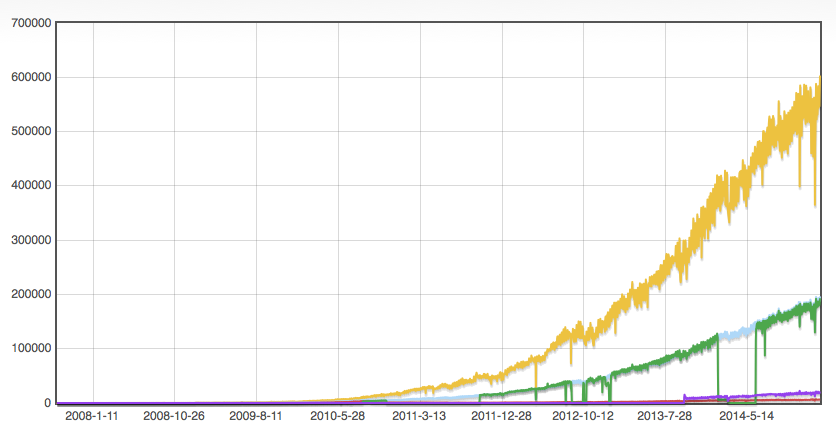
Gyazo (2015/9)

Alexaデータ (2013/11/14)
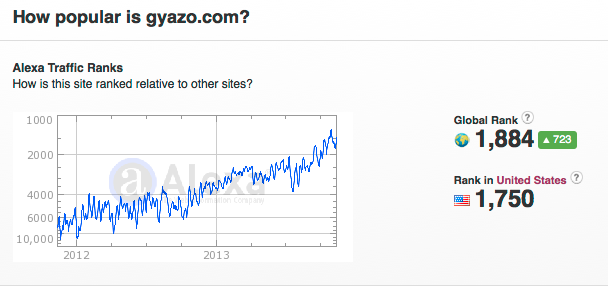
Alexaデータ (2014/1/15)
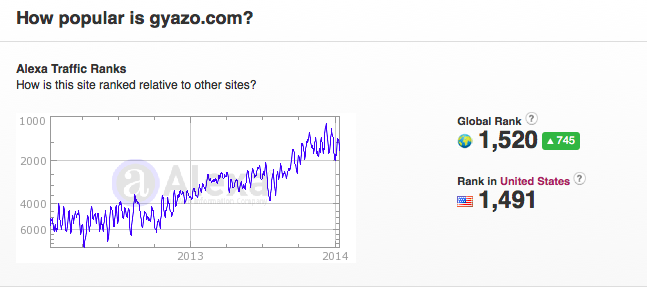
Alexaデータ (2014/10/27)
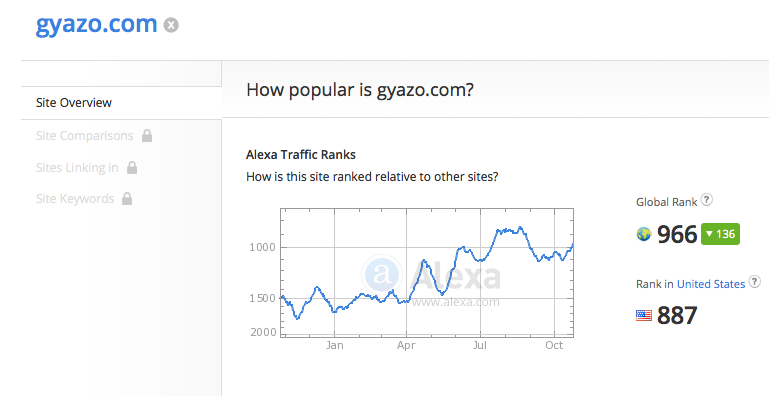
Alexaデータ (2015/3/3)

Alexaデータ (2017/3)



セールスピッチ

Gyazo導入企業

Gyazoの成長

関連サービス

Gyazoの歴史
2007/9 増井が個人で運用開始
2010? Nota inc. でサポート開始
2014/4 Gyazo GIFリリース
2014/11 資金ゲット
2015/7 IvySearchリリース
2016/7 OCR リリース
機能は画像をアップするだけ
関連URLなどを保存
関連画像の表示
ビジネスモデル
フリーミアム
広告
Gyazoのデータ量
月間アップロード2400万枚
月間ユニークユーザ1000万
Gyazoの運用環境
海外サーバ
Elastic Searchによる全文検索
MongoDBでメタデータ管理
画像検索の考察
検索の分類
知ってるものの検索
見たことがあるものにアクセス
e.g. 古い写真の検索, ファイル検索
知らないものの検索
見たことがないものを捜す
e.g. Google検索, 写真素材検索
知ってるものの検索
一度見たことがある
関連情報を覚えている
みつからないと腹がたつ
例
古い写真
古い書類
知らないものの検索
存在するかどうかも不明
みつからなくても平気
例
知らない情報
写真素材
画像の検索方法
イメージ中身で検索
メタデータで検索
両者の比較
自分の写真の検索の方が機会は多い
画像をアップロードしたことは覚えている
全く知らない画像を検索することは少ない
関連情報からの検索が有用な場合は多い
「豪邸」とか「喧嘩」とかを検索できるか?
「赤坂で会った人」を検索できるか?
漠然としたことは覚えている
日時
場所
地名、緯度経度
人物
環境
温度、音楽、...
関連キーワード
関連情報検索
「芋蔓式」検索が大事
IvySearch

IvySearch

デモ: IvySearch
例: 「請求書」
例: 「自転車」
例: 「名山」
例: 「イギリス」
例: 「テンセグリティ」
実装
ElasticSearchを利用
kuromojiで形態素解析
json{ "cluster_name" : "ivy", "status" : "green", "timed_out" : false, "number_of_nodes" : 5, "number_of_data_nodes" : 4, "active_primary_shards" : 16, "active_shards" : 32, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0} Spec
8 vCPUs, 52 GB memory, 1TB SSD
運用
Gyazoったときはキーワードも入れる
写真をDrag&Dropしてコメントを書く
芋蔓検索の強み
自分のコンテンツなのにナビゲーションが面白い
意外と検索に成功する
関係ないものが出てきて面白い
セレンディピティ支援
芋蔓検索を有効にするコツ
どんなものでも画像でセーブ
コメントかキーワードを自分で書いておく
全部にキーワードをつけない
つけすぎると大変なことに
自動があってももちろんかまわない
タイムスタンプやOCRは有効
キーワード付加は面倒?
それほどでもない
と増井は思う
便利さの方がはるかに上回る
Scrapboxと芋蔓検索
近傍検索システム
近傍の情報をたどって目的の情報に接近
時間的近傍
内容的近傍
位置的近傍

Scrapboxとは
フレキシブルな共有ノート
芋蔓的情報検索

デモ: Scrapbox
Scrapboxの特徴
WYSIWYGなWiki
複数ユーザ同時編集
Gyazo画像の活用
ページ代表画像の利用
ページとタグの区別が無い
階層構造なし
双方向リンク
柔軟で簡単なScrapbox記法
強力な文字装飾記法
情報整理と検索
整理には分類が必要?
検索できれば整理したのと同じ
分類/階層化の必要はない
e.g. IvySearch
情報管理の難しさ
大量の情報を分類するのはほぼ不可能
階層的整理は困難
整合性の問題
分類不能なもの
複数カテゴリに分類したいもの
階層的情報管理
ファイルシステムや情報整理で常識的
分類や階層化で悩む
Evernote
各種の「ノート」を「ノートブック」で管理
ノートはメモでも画像でも何でも
複数のノートブックを「スタック」で管理
ノートに「タグ」を付加可能
管理や分類のルールが面倒
Mindmap

スプートニクとソユーズとボイジャーが全然別物になってる
Scrapbox
ページとリンクだけを利用
階層思考や分類思考を排除
とにかく書いてキーワードに印をつける
タグはページで代用する
Scrapboxの特長
シンプルなのに強力
あらゆる情報の芋蔓検索
例: /masuilab
例: /prog-examples
例: /masuifamily
例: /UIPedia
文献情報検索システム
定型的な情報しか入力できない
AとBは夫婦、とか入力できるか?
例: CGVIのサイトを生成
その他の芋蔓検索
dshelf: 書籍の芋蔓検索

デモ: dshelf
Pivotty: 映画の芋蔓検索

デモ: Pivotty
結論
芋蔓検索の活用
一般的な検索手法との融合が課題